-
트라이(Trie)란 뭔가?
간단하게 얘기하면 문자열 집합을 위한 '트리 자료 구조'다. prefix tree, digital search tree, retrieval tree 등으로 불리는 자료 구조이며, retrieval tree 에서 트라이(Trie)라는 단어가 유래했다고 알려져 있다. 이진 탐색 트리에서는 원하는 원소를 찾는데 O(logN) 만큼의 시간이 걸린다. 하지만, 원하는 원소(문자 하나)가 아닌, 문자열을 찾기 위해서는 문자열의 길이 만큼 비교를 해야하기 때문에 O(MlogN) 만큼의 시간이 걸린다(M은 문자열의 길이). 이처럼 문자열을 찾는데 기존에 있던 자료 구조로는 시간이 오래 걸리기 때문에 '더 빠른 시간 내에 문자열을 찾아낼 수 있는 자료 구조'로써 만들어 진 것이 트라이(Trie)다.
트라이(Trie)의 구조와 작동 원리
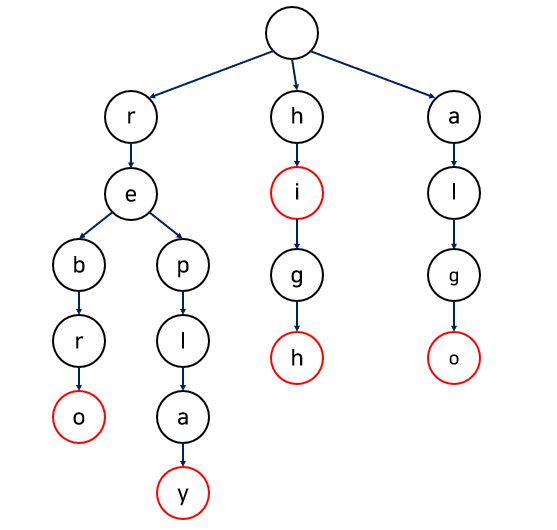
트라이(Trie) 예시 트라이는 집합에 포함된 문자열의 접두사(prefix)에 대응되는 노드들이 서로 연결되어 있는 트리 구조를 가진다. 문자열의 다음 문자가 현재 문자의 자식 노드가 되고, 문자열의 마지막 문자는 위 예시의 빨간색 부분 처럼 스스로 문자열의 끝임을 알리는 값을 가진다.
트라이로 문자열을 탐색하는 방법은 다음과 같다. 루트 노드로부터 연결된 노드가 있는지 검색하고 있다면 계속해서 노드를 타고 간다. 문자열의 끝을 의미하는 빨간색 노드까지 모든 문자를 모으면 찾고자 하는 문자열이 나온다.
트라이(Trie)의 장단점
장점
- 문자열 검색 속도가 빠르다.
단점
- 필요 메모리 크기가 크다. (총 노드 개수 * 포인터 배열 개수 * 포인터 크기)
- 이런 메모리 효율을 개선한 Radix Trie 라는 자료 구조도 있다. 생김새는 아래와 같다.

Radix Trie - Wikipedia 트라이(Trie)의 시간 복잡도
문자열의 최대 길이가 M이라고 할 때 탐색/삽입에 O(M)의 시간 복잡도를 가진다. 탐색과 삽입할 때 최악의 경우 문자열의 길이 만큼 노드를 따라가면 되기 때문에 O(M) 만큼의 시간이 걸린다.
사용처
- 검색 엔진
- 문서 파일에서 문자열 검색 시
구현 방법
- 노드
- 현재 문자 - 자식(key - value)로 자식 노드에 대한 포인터
- 문자열의 끝임을 알리는 변수
- 삽입
- 루트 노드부터 경로를 타고 가며 삽입 문자열의 첫 글자부터 탐색
- 해당 글자의 노드가 없을 때까지 다음 글자로 넘기며 자식 노드를 타고 간다.
- 현재 글자에 대한 노드가 없는 경우 노드 생성한다.
- 문자열 끝에 도달할 때까지 2~3번을 반복한다.
- 문자열의 글자에 대한 노드를 모두 생성했으면 마지막 노드에 끝을 알리는 변수 값 저장
- 검색
- 루트 노드부터 경로를 타고 가며 검색 문자열의 첫 글자부터 탐색
- 현재 글자의 노드를 찾으면 다음 글자로 넘긴다.
- 문자열 끝까지 노드를 찾으면 종료
Reference